很长一段时间,我曾以为像定时器这样基础的功能,操作系统会有一个完备的实现。当需要开启一个定时任务的时候,会有一个优雅的、如下形式的接口:
1 | typedef void (*callback)(void*); |
可是事与愿违,Linux下不存在这样的接口。
Linux上的定时函数
要想使用上面那样的定时器功能,我们必须利用Linux上现有的定时通知函数,封装一个定时器。Linux上的定时通知函数五花八门,要封装我们自己的定时器,首先需要选用一个定时通知的函数。查阅资料整理出了Linux上所有的定时函数,如下表:
| Function | Type | Precision | Remark |
|---|---|---|---|
| sleep(3) | unsigned int | second | |
| usleep(3) | useconds_t | microsecond | |
| nanosleep(2) | struct timespec | nanosecond | |
| clock_nanosleep(2) | struct timespec | nanosecond | It differs in allowing the caller to select the clock against which the sleep interval is to be measured, and in allowingthe sleep interval to be specified as either an absolute or a relative value. |
| alarm(2) | unsigned int | second | SIGALRM |
| setitimer(2) | struct itimerval | microsecond | SIGALRM |
| timer_settime(2) | struct itimerspec | nanosecond | notify method : struct sigevent |
| Timerfd API | File descriptor | nanosecond | From linux kernel 2.6.25 |
前四个函数比较鸡肋,会让调用线程挂起,原地等待定时器超时,否定。
alarm()和setitimer(),它们的通知机制采用了信号SIGALRM,由于SIGALRM信号不可靠,会造成超时通知不可靠,而且多线程中处理信号也是一个麻烦事,也不考虑。
timer_create()/timer_settime()系列函数是POSIX规定,精度达到纳秒级,提供了一个数据结构struct sigevent可以指定一个实时信号作为通知信号,同时也可以设置线程ID,将信号传递到指定的线程。相比前两个函数,有了不小的改进,可以作为一个备选的实现,但是可以预见到封装起来不会很轻松。此外使用此系列的函数,需要链接librt库。
事实上,我们遗漏掉了几个同样具有定时的功能的API——多路复用。在Linux上的多路复用机制有select/poll/epoll几种,它们轮询时都允许指定一个超时时间,如果在指定时间内,监控的事件没有到达,轮询函数会超时返回。精度也足够用,poll/epoll是毫秒级的(millisecond),select超时参数是struct timeval,是微秒级的(microsecond)。
选择epoll的优势很明显,能将定时功能完美的融入已有的event loop里,同时epoll有着天然的高并发的能力,millisecond级的精度也足够用。
获取当前时间
要实现一个定时器,有了定时函数,我们还需要选用一个获取时间的函数。同样地,这些函数我也整理了一下:
| Function | Type | Precision | Remark |
|---|---|---|---|
| time(2) | time_t | second | |
| ftime(3) | struct timeb | millisecond | obsolete |
| gettimeofday(2) | struct timeval | microsecond | |
| clock_gettime(2) | struct timespec | nanosecond | |
| Time Stamp Counter | 64-bit register | CPU related | on all x86 processors since the Pentium(TSC) |
time()精度太低,不合适。
ftime() 毫秒级精度,但是被废弃了,也不合适。
gettimeofday() 精度达到微秒级,并且在x86-64平台上该函数的调用不是系统调用(vdso),似乎很合适,不幸的是POSIX.1-2008中也将这个函数废弃了。
Time Stamp Counter 使用汇编指定获取时间戳的计数器,精度应该是最高的,效率可能也应该是最高的,一条汇编指令rdtscp(相比rdtsc,rdtscp可以避免,因为cpu乱序执行带来的误差问题)即可。是可以作为一个选择的,腾讯的libco就是优先使用这个方法获取时间的。
clock_gettime() 。默认是nanosecond 级精度,是系统调用(_sys_clock_gettime()),会有开销。调用频繁的话,可能造成损失性能。但是Linux 2.6.32后可以指定参数CLOCK_REALTIME_COARSE和CLOCK_MONOTONIC_COARSE,粗粒度地获取时间,而不需要发生上下文切换(和gettimeofday()一样也是vdso技术,https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html/reference_guide/sect-posix_clocks#CLOCK_MONOTONIC_COARSE_and_CLOCK_REALTIME_COARSE)。使用_COARSE后缀获取的时间,精度是millisecond级。对我们来说也够用了。
要对clock_gettime系统调用的开销有一个直观的感受的话可以,借助于strace工具,利用-T参数可以追踪每个系统调用的时间开销,比我我的环境上CLOCK_MONOTONIC获取时间的开销大概是50微秒
换成CLOCK_MONOTONIC_COARSE方式再去获取时间,用strace就追踪不到了。
定时器的设计
有了获取时间函数clock_gettime和定时函数epoll之后,我们就可以开始设计定时器了。首先明确一点,epoll和其他的定时通知函数一样,一次也只能设置一个超时时间,依然不能满足我开篇提出的需求。
主流的做法是利用一个容器保存所有设置的超时时间,将容器里最快的超时的时间设置为epoll_wait的超时时间。比如,我先后设置了1400ms,800ms,300ms,2900ms,那么下一次事件循环就将epoll_wait的第四个参数设置为300ms。
如果用链表保存的话,每次设置定时器都要遍历一遍链表才能选到最快超时的那个时间,复杂度太高,如果设置了定时器特别多的话,这样的开销不能接受。
要像O(1)的时间获取到最小的哪个值,用最小堆保存超时时间正合适,效率大大提高。事实上libevent就是这么实现的(C语言实现的min_heap_t)。
最小堆实现
先实现一个类Timer表示每一个被添加的定时,构造时需要一个millisecond为单位的超时时间,一个回调函数,一个回调函数的参数。为了简化实现,我测试用的超时的回调函数,并未使用回调函数的参数,但也没有去掉,仅仅是占个坑的作用。本来是想打算把args抽象,将Timer写成模板类,防止本末倒置,本文仅为演示定时器的实现,越简单越好。
expire时间用的是相对系统启动的时间,是一个不可以设置的恒定的时间(nonsettable monotonic clock),而不是用的真实的时间(Wall time ,墙上时间),因为这个时间可能会随着设置系统的日期时间而发生跳跃性的改变。
1 | class Timer |
TimerManager是用户操作的接口,提供增加,删除定时器的功能。STL中提供能优先队列,直接可以拿来用。
1 | class TimerManager |
addTimer()参数和Timer构造函数一直,实现就是构造一个Timer然后加入到std::priority_queue后,返回Timer指针。
delTimer() 删除一个指定的Timer,由于priority_queue没有提供erease()接口,因此删除Timer的操作,我这里采用了新建一个priority_queue的做法,复杂度O(n)。
getRecentTimeout()获取一个最近的超时时间(超时时间 = 优先队列里的时间 - 当前获取的系统启动时间)。如果这个值小于0,那么说明这个定时器已经超时了,将其置为0,稍后的epoll_wait将会立马返回。
takeAllTimeout() 函数,处理超时的定时,并回调其绑定的回调函数。由于超时的可能不止一个定时,需要用一个循环遍历所有超时的Timer,一一处理。
getCurrentMillisecs()对clock_gettime()的封装,获取到的struct timespec转换为millisecond。
这两个类的完整实现,我放到了Github上了:https://gist.github.com/baixiangcpp/b2199f1f1c7108f22f47d2ca617f6960。使用的时候,只需要在你的主循环里,把epoll_wait的超时参数设置为TimerManager::getRecentTimeout(),每次epoll_wait()返回后,处理一下超时事件TimerManager::takeAllTimeout()。
使用示例:
1 | int dispatch() |
时间轮实现
另外一种常见的定时器设计使用的存放超时时间的容器叫做”时间轮”。微信的开源项目libco中使用的就是这种数据结构。
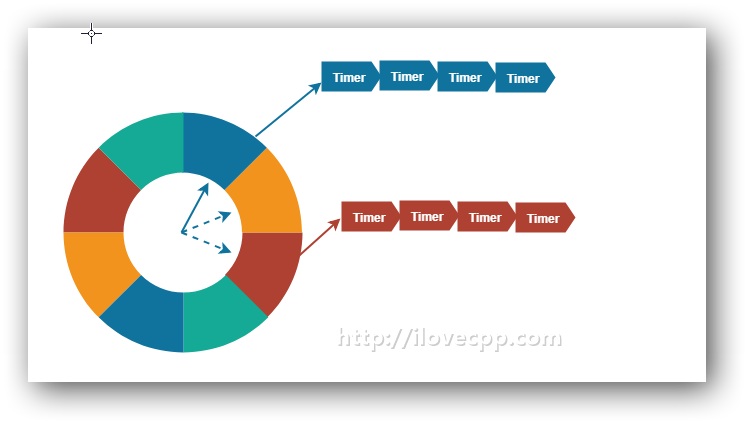
对于时间轮的实现,Timer依然是存放在链表上,但是借助了hash的思想,将相同间隔(或者相同周期的整数倍)的超时Timer放在同一个时间轮子上的槽(slot)上。时间轮上有一个指针,按照一个基准的频率(比如1ms,5ms,10ms等,libco中设置的是1ms)向前移动。这个基准的频率就是传递给epoll_wait()超时的值,也是定时器精度的基本单位。
1 | class Timer |
时间轮中的Timer类和最小堆中的实现,多了两个参数,rotations表示时间轮转多少圈后当前的Timer会触发,slot表示当前的Timer应该挂在对应的槽指向的链表上。成员函数比较简单,不多赘述。
1 | class TimeWheel |
curslot_表示时间轮当前指向的那个slot。nslosts_表示这个时间轮拥有多少个slot,不要上图迷惑了,实际上slot会远远超过这8个。要想效率足够高,slot就要越大,当然占用的内存也会越大(现代计算机,这点内存可以忽略不计),libco默认使用了 60 * 1000 个slot 。
addTimer()是添加一个Timer到TimeWheel上,需要根据传递的timeout参数,计算出该Timer所对应的slot (slot = (curslot_ + (timeout % nslosts_)) % nslosts_;) ,还有到这个Timer超时时间轮的指针需要转过的圈数(timeout / nslosts_)。
delTimer() 根据Timer*参数,删除时间轮上对应的Timer。
tick() 时间轮的指针走动一下。同时遍历当前slot上链表里的每一个Timer,如果Timer的圈数大于0,将Timer里的圈数-1,否则激活这个Timer。
takeAllTimeout() 是必要的,由于误差的存在,每次epoll_wait超时后(一个基准频率),时间轮可能需要走动好几步。如果每次epoll_wait后直接tick()而不是takeAllTimeout(),会导致误差一直被累积,时间轮上剩余的定时器被滞后触发。
时间轮的实现我也放到了Github上:https://gist.github.com/baixiangcpp/63278c0087201a655f940ab8de543abd。使用方式和之前的最小堆实现的基本是一样的。
使用示例:
1 | int dispatch() |
最小堆和时间轮的时间复杂度,如下:
| Type | add | exec |
| :- | :- | :- | :-|
| list | O(1) | O(n) |
| min-heap | O(lgn) | O(1) |
| time wheel | O(1) | O(n) |
这里我只列出添加定时器和触发定时器的时间复杂度,因为这几种实现中,删除一个定时器可以优化到O(1)的时间复杂度————把其对应的回调函数置空。前面的例子我没有这么做,仅为展示,有兴趣的话可以自行修改。
乍看下来,时间轮的复杂度和链表是一样的。其实不然,时间轮上触发一个定时器,仅仅是理论上的O(n),只要slot的数量设置合理,时间复杂度会下降至接近O(1)。
可以根据实际需要,选择合适的定时器容器。
要不要用Timerfd?
开篇的表格里有提到,从Linux2.6.25开始,timerfd系列API,带来了一种全新的定时机制。把超时事件转换为了文件描述符,当超时发生后该文件描述符会变成可读。于是超时事件就变成了普通的IO事件。如果未对timerfd设置阻塞,对其read操作会一直阻塞到超时发生。此外timerfd的精度达到了纳秒级。不考虑跨平台等因素,这是一个非常不错的选择。
libevent2.1的源码里也支持timerfd了,在版本说明里也很明确了说明了使用多路复用的超时参数和使用timerfd之间的差异 ,它使用了两个词”efficient”和”precise”,分别表示这种实现之间的差异,我想着这还是非常有说服力的。
每个超时事件独享一个timerfd
如果对于每一个超时事件都用timerfd_create()创建一个对应的fd,放到epoll中统一管理。这样的做法是不合适的。每增加一个定时事件,都需要额外的3个系统调用:

此外,文件描述符还是稀缺的资源,每个进程能够使用的文件描述符是受系统限制的,如果定时器过多,会造成严重的浪费。
这种方式的定时器,比较容易实现,这里我就不再浪费篇幅了。
所有超时事件共享一个timerfd
libevent就是使用的这种方式。定时时间仍然使用最小堆来保存,每个event loop共享同一个timerfd。每次事件循环之前,取出最近的一个超时的时间,将这个timerfd设置为这个超时时间。
1 | int epoll_dispatch( ...) |
这样的改进规避了前一种方式提到的造成文件描述符资源浪费的问题,仅仅需要1个额外的文件描述符。
额外的系统调用从额外的3个,降到了1个。而且还有改进的空间,只有当栈顶的timeout变化时,才调用timerfd_settime()改变。
这种方式实现的定时器,精度提高了但是多了1个额外的系统调用。libevent把选择权给了用户,用户可以根据实际情况在创建event base的时候是否配置EVENT_BASE_FLAG_PRECISE_TIMER宏而选择使用哪个定时器实现。
总结
std::priority_queue是一个容器适配器,底层的容器默认使用的std::vector(make_heap())。但是这不意味着往std::priority_queue插入一个元素的开销是O(n),C++标准对此实现有要求,可以放心大胆的去用。但是std::priority_queue没有提供高效删除元素的接口,我们可以通过将回调函数置空的方式,以O(1)的时间复杂度实现删除。
以C++实现的muduo网络库使用的是std::set集合存放Timer:
1 | typedef std::pair<Timestamp, Timer*> Entry; |
实际上std::set实现应该是二叉搜索树,因此效率可能会比用std::priority_queue略差一点(《linux多线程网络编程》 8.2 )。
此外,libev 允许使用一个宏EV_USE_4HEAP指定以一个4-heap的数据结构保存定时器,据说效率更高,我也没有测试。
以上就是目前一些c/c++语言实现的网络库里边定时器常用的设计手法。